
Sensitive data management best practices explained in a practical, structured way can make the difference between a secure organization and one that faces regulatory fines, reputational damage, or data breaches. For data privacy and compliance professionals, the stakes have never been higher. Regulations like GDPR, CCPA, and HIPAA demand that organizations know exactly where their sensitive data lives, who accesses it, and how it is protected. Yet many teams still rely on ad hoc processes that leave gaps.
This guide walks you through four actionable steps to build a robust sensitive data management program. Each step is grounded in real-world practice, not theory. Understanding what a data audit is and how it works provides the foundation for everything that follows.
Key Takeaways
- Classify all data assets by sensitivity level before building any protection strategy.
- Automate discovery tools to find sensitive data hiding in unexpected locations.
- Map data flows to identify exposure points across systems and third parties.
- Implement role-based access controls and review them on a quarterly cycle.
- Continuously monitor and audit your data environment rather than treating compliance as one-time.
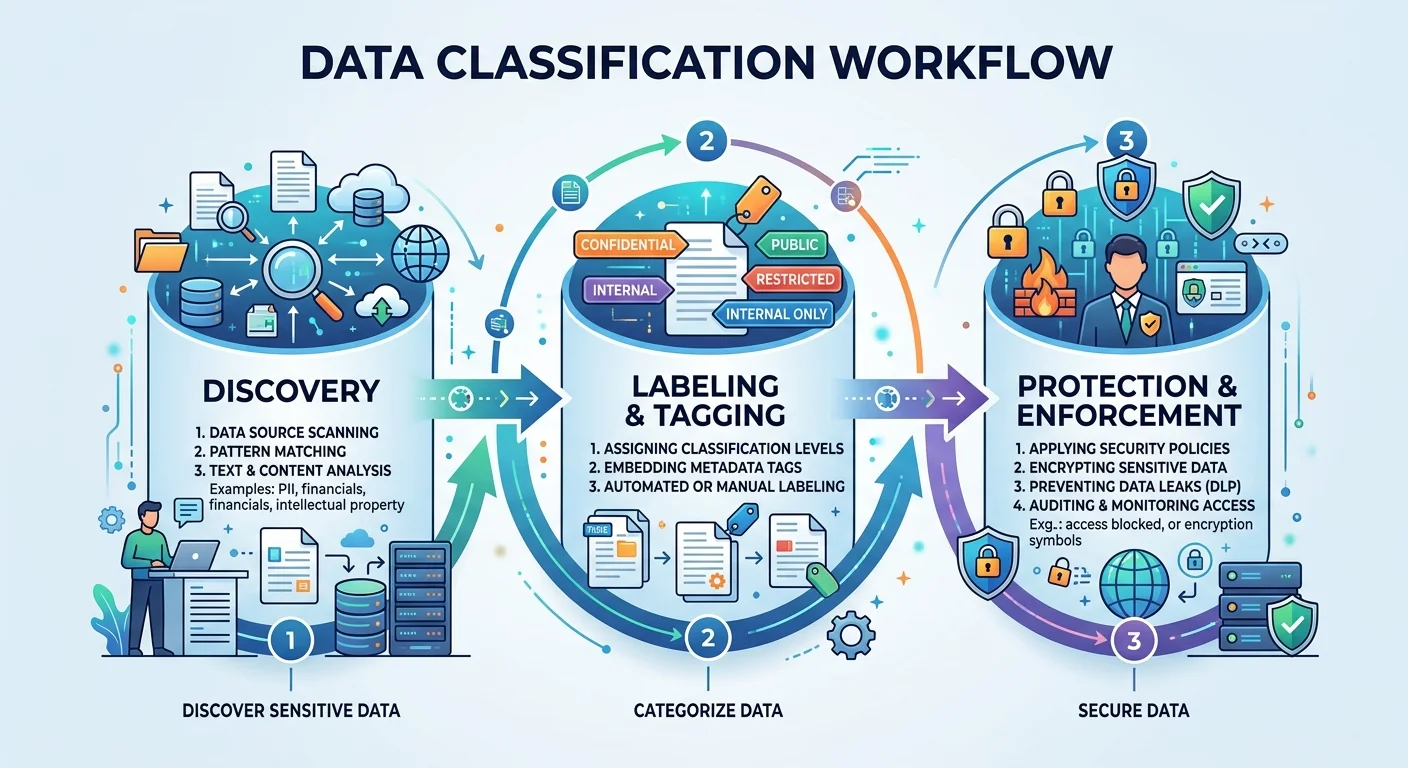
Step 1: Discover and Classify Your Sensitive Data
You cannot protect what you do not know exists. The first step in any sensitive data management program is a thorough discovery process. Organizations typically store data across dozens of systems: cloud storage buckets, SaaS applications, on-premises databases, email servers, and employee laptops. A 2023 IBM report found that the average organization stores sensitive data in over 20 different repositories. Without a systematic approach, sensitive records slip through the cracks and remain unprotected.
Automated Discovery Tools
Manual data inventories are outdated and error-prone. Automated discovery tools scan structured and unstructured data sources to identify sensitive fields like Social Security numbers, credit card numbers, health records, and biometric identifiers. Products from vendors such as Varonis, BigID, and Spirion can crawl databases, file shares, and cloud environments in hours rather than weeks. When choosing a tool, verify that it supports the specific data types and regulations relevant to your industry. Integration with your existing tech stack matters too; reviewing the best API management tools can help you connect discovery outputs to your broader data governance platform.
Run discovery scans on a monthly schedule, not just during annual audits, to catch new data stores as they appear.
Classification Frameworks
Once you have discovered your data, you need a classification schema. A common approach uses four tiers: Public, Internal, Confidential, and Restricted. Each tier maps to specific handling requirements. For example, Restricted data (think payment card information or patient health records) demands encryption at rest and in transit, strict access controls, and fast audit logging. Internal data might only require basic access restrictions. Document your schema in a formal policy that every team can reference. This classification directly informs your protection strategy and makes regulatory reporting far more straightforward.
Step 2: Map Data Flows and Control Access
Data Flow Mapping
Knowing where sensitive data sits is only half the picture. You also need to understand how it moves. Data flow mapping traces the journey of sensitive records from collection point to storage, processing, sharing, and eventual deletion. A healthcare organization, for instance, might collect patient data through an online portal, store it in a cloud database, share it with an insurance processor via API, and archive it on a separate system after 12 months. Each handoff represents a potential exposure point. Teams following our guide on how to run a dataset privacy audit step by step will find data flow mapping a natural extension of the audit process.
Document every data flow in a visual diagram. Include third-party processors, subprocessors, and any cross-border transfers. Under GDPR Article 30, organizations must maintain records of processing activities. Even if your organization is not subject to GDPR, this exercise reveals redundant data copies, unnecessary sharing arrangements, and systems where sensitive data has accumulated without oversight. It is one of the most revealing exercises in the sensitive data management best practices explained throughout this guide.
Third-party data sharing is a leading cause of breaches. Verify that every vendor receiving sensitive data has contractual obligations and appropriate security controls.
Access Control Policies
With data flows mapped, you can implement access controls that follow the principle of least privilege. Every user, application, and service account should have access only to the data it needs to perform its function. Role-based access control (RBAC) is the standard approach: define roles, assign permissions to roles, and assign users to roles. Review access grants quarterly and revoke permissions immediately when employees change roles or leave the organization. A 2024 Verizon DBIR found that privilege misuse accounted for a meaningful share of insider threat incidents, underscoring why access hygiene matters.
Multi-factor authentication should be mandatory for any system containing Confidential or Restricted data. Pair MFA with session timeouts and IP-based restrictions where practical. For API-level access, use OAuth 2.0 tokens with short expiration windows rather than static API keys. These controls reduce the blast radius if credentials are compromised and make it significantly harder for unauthorized parties to exfiltrate sensitive records.
Step 3: Implement Technical and Organizational Protection Measures
Encryption and Data Masking
Encryption is the backbone of sensitive data protection. At minimum, encrypt all Confidential and Restricted data at rest using AES-256 and in transit using TLS 1.2 or higher. For databases, consider column-level encryption for particularly sensitive fields so that even database administrators cannot view raw values without explicit key access. Key management deserves serious attention: store encryption keys in a hardware security module (HSM) or a cloud-managed key service, and rotate keys on a defined schedule. Poor key management undermines even the strongest encryption.
"The strongest encryption is worthless if your key management practices are weak."
Data masking and tokenization provide additional layers. Use dynamic masking in development and testing environments so that engineers never work with real sensitive data. Tokenization replaces sensitive values with non-reversible tokens, which is particularly useful for payment processing systems aiming for PCI DSS compliance. Both techniques reduce the number of systems where actual sensitive data exists, shrinking your attack surface. For small businesses working through a data compliance checklist, tokenization can be a practical, cost-effective first step.
Never use production data in non-production environments. Synthetic data generation tools can create realistic test datasets without any privacy risk.
Organizational Safeguards
Technology alone does not solve the problem. Your organization needs clear policies, regular training, and defined responsibilities. Assign a Data Protection Officer or equivalent role to own the sensitive data management program. Create written policies for data retention, data sharing, incident response, and acceptable use. Train all employees who handle sensitive data at least annually, and tailor the training to their specific role. A customer support agent handling personal information needs different guidance than a database administrator.
Data Loss Prevention (DLP) tools bridge both worlds. Configure DLP rules to detect and block sensitive data from leaving the organization through email, cloud uploads, or USB devices. Modern DLP platforms can classify data in real time and apply policies based on your classification schema. Pair DLP with security information and event management (SIEM) systems to correlate alerts and identify patterns that suggest data exfiltration attempts.
Step 4: Audit and Monitor Continuously
Ongoing Audits and Risk Assessments
Sensitive data management best practices explained in static policies become outdated quickly. New systems get deployed. Business processes change. Regulations evolve. Continuous auditing transforms your compliance posture from reactive to proactive. Schedule formal audits at least twice per year, supplemented by automated monitoring that runs daily. Each audit should verify that classification labels remain accurate, access controls are still appropriate, encryption is properly configured, and data retention schedules are being followed.
Risk assessments should accompany every significant change to your data environment: a new SaaS vendor, a database migration, a new data collection point on your website. Organizations subject to GDPR should conduct Data Protection Impact Assessments (DPIAs) for high-risk processing activities. Using dedicated privacy risk assessment tools for GDPR compliance can standardize this process and produce audit-ready documentation. These assessments are not bureaucratic overhead; they consistently surface risks that would otherwise remain hidden until something goes wrong.
Regulatory expectations are shifting toward continuous compliance. Periodic audits alone no longer satisfy most regulators.
Incident Response Readiness
Even with strong controls, breaches happen. Your incident response plan should specifically address sensitive data scenarios. Define escalation paths, notification timelines (GDPR requires 72-hour breach notification to supervisory authorities), forensic investigation procedures, and communication templates for affected individuals. Test the plan through tabletop exercises at least once per year. During these exercises, simulate realistic scenarios: a compromised database credential, a misconfigured cloud bucket exposing personal records, or a phishing attack targeting an employee with admin access.
Post-incident reviews are equally valuable. After every real incident or simulated exercise, document lessons learned and update your controls accordingly. Track metrics such as mean time to detect, mean time to contain, and number of records affected. These numbers tell you whether your sensitive data management program is improving over time. The organizations that handle breaches best are the ones that practice regularly, not the ones that assume their controls are sufficient.
Frequently Asked Questions
?How often should I run automated discovery scans on data stores?
?Is a four-tier classification schema right for every organization?
?How long does implementing a sensitive data management program take?
?What's the biggest mistake teams make with access control reviews?
Final Thoughts
Sensitive data management best practices explained in this guide represent a continuous discipline, not a one-time project. Discover your data, classify it, map how it flows, control who accesses it, protect it with encryption and policies, and audit everything regularly.
The organizations that invest in this cycle consistently experience fewer breaches and lower compliance costs. Start with what you have, improve incrementally, and treat every audit finding as an opportunity to strengthen your program rather than a failure to explain away.
Disclaimer: Portions of this content may have been generated using AI tools to enhance clarity and brevity. While reviewed by a human, independent verification is encouraged.


